Karun SharmaI am a final year Computer Science and AI student at Bennett University (GPA: 9.68/10), currently working as a Research Intern at Halmstad University under Shengzhi Li (llama team) and Dr. Prayag Tiwari, focusing on multimodal LLMs and any-to-any generation. Previously, I worked as an AI Engineer at TU Munich & SAP on automated UI testing frameworks, and as a Research Scholar at Georgia Institute of Technology on multimodal visual grounding. Prior to this, I worked at Zocket AI as a Computer Vision intern. My research interests lie in Multimodal Learning (Any-To-Any Modals), Vision-Language Models, and Embodied AI. |

|
Experience |

|
AI Engineer - TU Munich & SAP03 - 2025 Created a framework using AI Agents for automated UI Testing, handling flakiness. Added multimodal support to framework for End-To-End UI Testing. Made a pipeline for automated complex test case generation making the process at least 10x faster. |

|
Research Intern, Advisors: Shengzhi Li (Meta llama) and Dr. Prayag Tiwari09 - 2024 Working on multimodal LLMs and any-to-any generation models. Implemented multi-stage training for interleaved generation in MLLMs. Added SDXL support for DDPO into trl library for custom diffusion model training. Pre-trained Any-to-Any model on CC3M, WebVid and AudioCap for encoder side alignment (on 8TB Data). Working on dataset and reward modeling to improve scientific question generation on long sequences. |

|
Research Scholar - Georgia Institute of Technology08 - 2024 Worked on multimodal visual grounding using LLMs and lightweight vision models. Improved grounding accuracy and contextual understanding in VLMs. Surpassed GPT-4V by mIoU of 0.415 on RefCOCO for grounding. |
|
|
Computer Vision Intern - Zocket AI02 - 2024 Trained various dual encoder multimodals for the task of complex advertisement recognition. Achieved Detection Accuracy of 94% (while ensuring good recall) on latest advertisement data from the web. Built custom model for highly accurate segmentation and fast background removal, surpassing SOTA models. |
ResearchI'm interested in Computer Vision, Multimodals, Machine Learning, Optimization |

|
Think to Ground: Improving Spatial Reasoning in LLMs for better Visual GroundingKarun Sharma, Vidushee Vats ICLR 2025: Workshop on Reasoning and Planning for Large Language Models, 2025 website / Improving spatial reasoning in LLMs for better visual grounding. This work focuses on enhancing the spatial understanding capabilities of large language models to improve their performance on visual grounding tasks. |
|
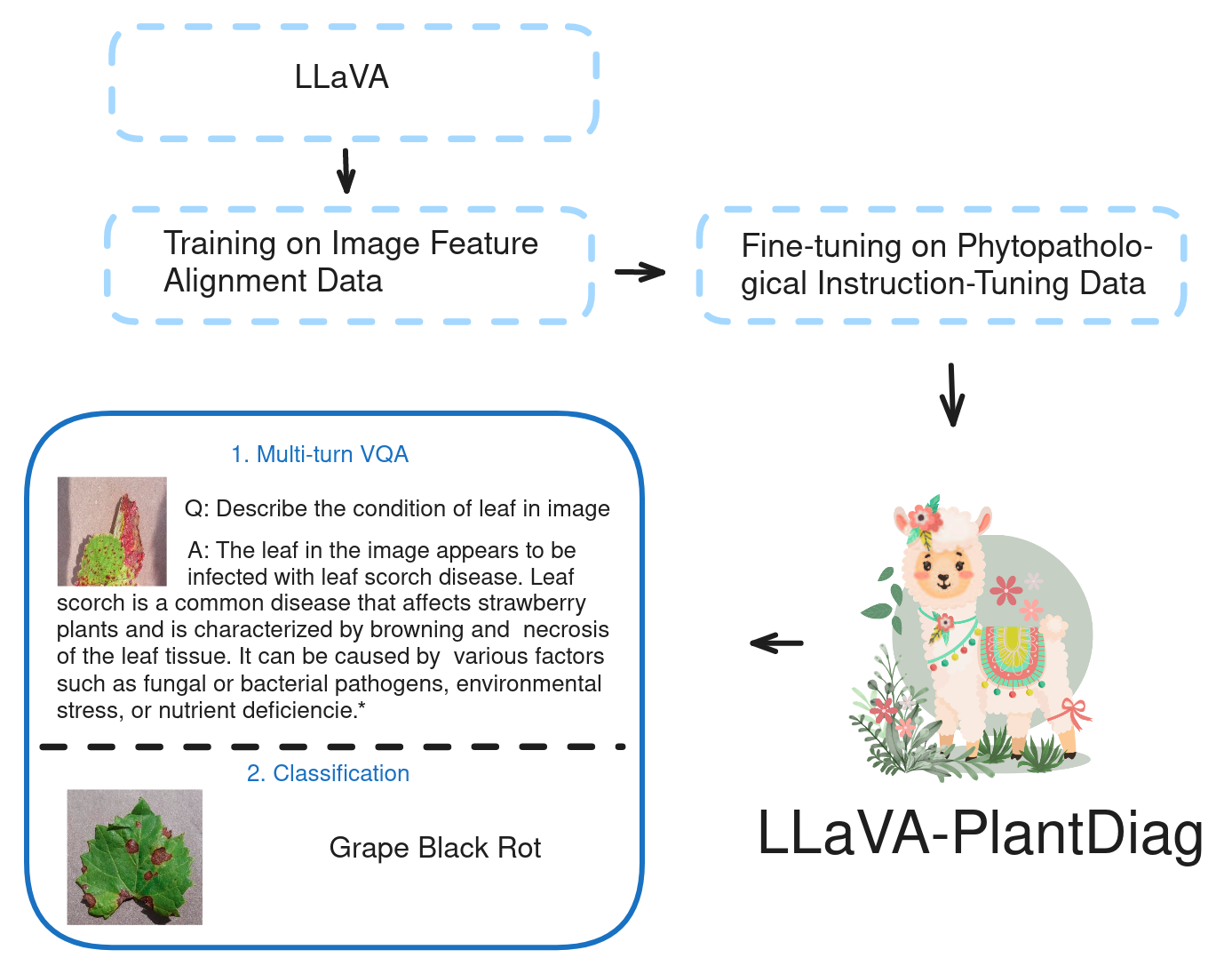
LLaVA-PlantDiag: Integrating Large-scale Vision-Language Abilities for Conversational Plant Pathology DiagnosisKarun Sharma, Vidushee Vats, Abhinendra Singh, Rahul Sahani, Dr. Deepak Rai, Dr. Ashok Sharma 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 2024 IEEE / website / LLaVA-PlantDiag, is a conversational AI system designed for plant pathology. We use visual instruction tuning for model finetuning. Our model outperforms others like GPT-4 Vision and Gemini, We also release first multimodal data on plant-pathology. |
|
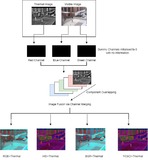
An Improved Hybrid Model for Target DetectionUmesh Gupta, Richa Golash, Vidushee Vats, Karun Sharma International Conference on Emerging Techniques in Computational Intelligence, 2023 IEEE / We worked on developing a refined model (YOLO and R-CNN Family) for detecting multiple objects by fusing thermal and visible images. The fusion techniques, including Multiscale Fusion, Channel-Based Fusion, and Blind Source Separation, significantly improve target detection in hazardous environments, enhancing safety and security in critical applications like autonomous driving and surveillance. |
Projects |
|
Design and source code from Jon Barron's website |